公告 3 Jun 2014: 代码暂时不能使用了, 我懒得去更新 ~
更正 19 Feb 2014: 不适用于中文字当地址名字的目标用户, 我有解决办法,但很懒改...
我们常常看见网站有 plusone g+1 的按钮:
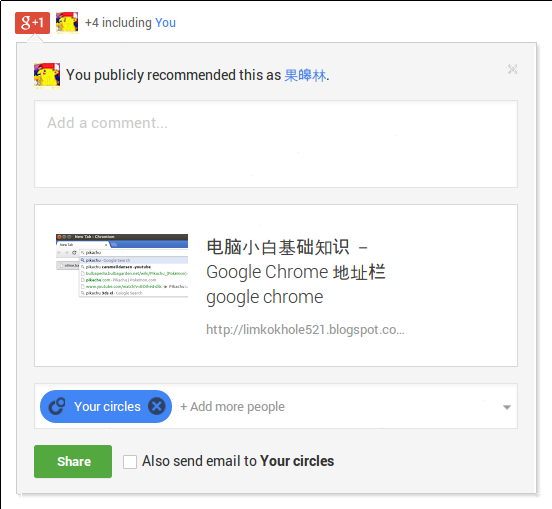
如果是自己按过 g+1 的话, 你的 Google Plus 帐号图片会出现在旁边, 朋友的话, 也有一定的几率在旁边看见:
至于那个数目
+3 是推荐在 Google Search 的次数.
分享是另一回事哦, 不影响 g+1 的数目, 不要混淆。你可以分享很多次。
如果是你或你的朋友的话 +1, 会显示在 Google Search 的下面, 不过, 仅限Google Plus 圈子里的朋友。如果是你自己+1,Google Search 会很快更新, 但是朋友的话,更新会花几天不定:
我这篇文章探讨的是 Google Search 的+1, 不是如下图所示的帖子的 +1哦, 不要混淆。
还有一点, g+1的按钮不限于别的网站看到的, 因为在 Google Plus 专页也能按 g+1 推荐在 Google Search。 只不过按钮不一样而已。如下图所示, +7047448 按钮。
你的 Google Search +1 过的历史可以在自己专页 的 +1 栏目看见, 当然你也可以看见别人的。
可是大多数人的隐私设定都是隐藏了 +1 的栏目。
现在我就教你简单的步骤来实现窥看:
步骤 1.
进入你要窥看的目标专页。比如说如图中的例子,LadyGaga专页。
步骤 2.
(i) 在那个页面随便一个地方用滑鼠按右键, 选 "Inspect Element"(检查元素)。
(ii) 有些浏览器直接按F12键就可以了。
步骤 3.
下面会出现新的窗口(你需要用滑鼠把那个窗口拖拉大一点),你要选 Console。 不同的浏览器(IE, Chrome, Firefox)图形设计都不同, 但都是一样的步骤, 找到 Console 点击就可以了。
Gogole Chrome 浏览器的 Console:
IE 浏览器的Console:
Firefox 浏览器的Console:
步骤 4.
把下面我写的代码全选,然后copy复制。记得要一字不漏copy, 代码很敏感的, 这个代码很长, 你可能需要scroll。
var FirstPage = true;
var AtleastOneItem = false;
var owner = "";
var index = 1;
function set_info() {
docBody.innerHTML = "";
docHead.innerHTML = '<head><meta http-equiv="Content-Type" content="text/html; charset=utf-8"></head>';
var user = "'s +1's";
if (owner) {
user = owner + user;
} else {
user = userid + user;
}
var profURL = "https://plus.google.com/" + userid;
plusones = "https://plus.google.com/s2/photos/profile/" + userid;
var profImg = img_create("0", "0", "100px", "100px", plusones, profURL);
docBody.appendChild(profImg);
var a_user = a_create(profURL, user);
var h3 = d.createElement("h3");
h3.style.display = "block";
h3.appendChild(a_user);
docBody.appendChild(h3); //tab title
}
function decodeEntities(s) {
s = s.replace(/\\u003d/g, "=").replace(/\\u0026/g, "&"); //my extra, /*/g for replace all
var str, temp = document.createElement('p');
temp.innerHTML = s;
str = temp.textContent || temp.innerText;
temp = null;
return str;
}
function img_create(m, b, w, h, sc, t) {
var i = d.createElement('img');
sc = sc || "";
t = t || "";
i.style.margin = m;
i.style.border = b;
i.style.width = w;
i.style.height = h;
i.src = sc;
i.title = t;
return i;
}
function a_create(h, t) {
var a = d.createElement("a");
if (h != null) a.href = h;
a.target = "_blank";
if (t != null) {
var link_text = d.createTextNode(t);
a.appendChild(link_text);
}
return a;
}
function div_create(t, w, h, f, ml, mh, ov, ws, pt, mw, m) {
var dv = d.createElement("div");
if (t != null) dv.style.textAlign = t;
if (f != null) dv.style.setProperty('float', f); //resevered word float failed in firefox
if (w != null) dv.style.width = w;
if (h != null) dv.style.height = h;
if (ml != null) dv.style.marginLeft = ml;
if (mh != null) dv.style.minHeight = mh;
if (ws != null) dv.style.whiteSpace = ws;
if (pt != null) dv.style.paddingTop = pt;
if (mw != null) dv.style.maxWidth = mw;
if (m != null) dv.style.margin = m;
return dv;
}
function li_create(lsp) {
var l = d.createElement("li");
l.style.listStylePosition = lsp;
return l;
}
function plusoneGui(title, hname, link, jpg, description) {
function loop(li2, title, hname, link, jpg, description) {
var li = li_create("outside");
var ul = d.createElement("ul");
ul.style.listStyleType = "none"; //rm bullet
var div3 = div_create("", "", "", "", "110px", "104px");
var title = title || "";
var hname = hname || "";
var link = link || "";
var jpg = jpg || "";
var description = description || "";
var im = img_create("0", "0", "100px", "100px", jpg, jpg);
var div = div_create("center", "100px", "100px");
var a = a_create(jpg);
var div2 = div_create("center", "102px", "102px", "left");
var a_title = a_create(link, title);
var span = d.createElement("span");
span.appendChild(a_title);
var div4 = div_create("", "", "", "", "", "", "hidden", "normal");
div4.appendChild(span);
var hname = d.createTextNode(hname);
var cite = d.createElement("cite");
cite.style.color = "#006621";
cite.style.fontStyle = "normal";
cite.appendChild(hname);
var div5 = div_create("", "", "", "", "", "", "", "", "2px");
div5.appendChild(cite);
var desc = d.createTextNode(description);
var span2 = d.createElement("span");
span2.appendChild(desc);
var div6 = div_create("", "", "", "", "", "", "", "", "", "509px", "1px 0 4px");
div6.appendChild(span2);
div.appendChild(im);
a.appendChild(div);
div2.appendChild(a);
li2.appendChild(div2); //left side pic
li.appendChild(div4); //title
li.appendChild(div5); //host
li.appendChild(div6); //desc
ul.appendChild(li);
div3.appendChild(ul);
li2.appendChild(div3); //right side text area
}
function loop2(ol, title, hname, link, jpg, description) {
var li2 = li_create("outside");
loop(li2, title, hname, link, jpg, description);
ol.appendChild(li2);
}
var ol = d.createElement("ol");
ol.start = "" + index; //int to str
loop2(ol, title, hname, link, jpg, description);
docBody.appendChild(ol);
index++;
}
var cid = "";
function parse_err(e) {
console.log("[" + e + "] Unknown parsing, please inform author.");
throw "stop execution";
}
function plusone_tab() {
if (cid) {
cid = "&ct=" + cid;
var m = document.getElementById("moreButton");
m.parentNode.removeChild(m); //rm prev btn
} else {
cid = "";
}
var pu = "https://plus.google.com/_/plusone/get?oid=" + userid + cid;
console.log("Requesting..." + pu);
var xhr = new XMLHttpRequest();
xhr.open("GET", pu);
xhr.setRequestHeader("Content-type", "application/x-www-form-urlencoded");
xhr.send();
xhr.onreadystatechange = function () {
if (xhr.readyState == 4) {
var da = xhr.status;
if (da == 200) {
var r = xhr.responseText;
var plusoneArray = r.split('\n');
cid = ""; //reset
d = document;
docBody = d.getElementsByTagName("body")[0];
docHead = d.getElementsByTagName("head")[0];
for (var i = 0; i < plusoneArray.length; i++) {
var line = plusoneArray[i];
if (line.indexOf('["1/') != -1) {
if (line.indexOf('",1,,,"') != -1) { //may empty desc, so it's not always got " surround
var quotes = '"';
} else { //no quotes
var quotes = '';
}
var lineArray = line.split('",1,,,' + quotes);
if (lineArray.length > 1) {
var l = lineArray[1];
var lineArray2 = l.split(quotes + ',,1');
if (lineArray2.length > 1) {
var dDesc = decodeEntities(lineArray2[0]);
var theRest = lineArray2[1];
var lineArray3 = theRest.split('",');
if (lineArray3.length > 3) {
//if out of bound, would still show and handle by gui
var dLink = decodeEntities(lineArray3[0].split(',["')[1]);
var dTitle = decodeEntities(lineArray3[1].split('"')[1]);
var dHost = decodeEntities(lineArray3[2].split(',"')[1]);
var dImg = decodeEntities(lineArray3[3].split('fallback_url\\u003d')[1].split('"')[0]);
AtleastOneItem = true;
for (i++; i < plusoneArray.length; i++) {
if (plusoneArray[i].indexOf('["1/') != -1) {
--i;
break;
} else {
if ((/^,[0|1],"\/\//).test(plusoneArray[i])) { // //,0,"//images OR ,1,"//images
var tmpImg = decodeEntities(plusoneArray[i].split('","')[1].split('"')[0]);
if (tmpImg) {
dImg = tmpImg;
break;
}
} else if ((/^,"/).test(plusoneArray[i])) { //StartsWith ,"
//possible when next page's last item use default img
cid = plusoneArray[i].split('"')[1];
}
}
}
if (AtleastOneItem) {
AtleastOneItem = false; //reset
if (FirstPage) {
FirstPage = false;
set_info();
}
plusoneGui(dTitle, dHost, dLink, dImg, dDesc);
} else {
console.log("No item found");
}
} else {
parse_err("2");
}
} else {
parse_err("1");
}
} else {
parse_err("0");
}
} else if ((/^,"/).test(plusoneArray[i])) { //StartsWith ,"
cid = plusoneArray[i].split('"')[1];
}
}
if (cid) {
console.log("Next cid:" + cid);
var moreBtn = d.createElement("input");
moreBtn.id = "moreButton";
moreBtn.type = "button";
moreBtn.value = "More 更多";
moreBtn.onclick = plusone_tab;
docBody.appendChild(moreBtn);
} else {
console.log("No data");
if (FirstPage) {
set_info();
var unav_text = d.createTextNode("Nothing :(");
docBody.appendChild(unav_text); //tab title
}
}
} else {
console.log("Failed");
}
}
}
}
function checkid() {
var ownerArray = document.querySelectorAll('[data-owner]');
if (ownerArray.length > 0) {
userid = ownerArray[0].getAttribute("data-owner");
if (userid) {
return userid;
}
}
}
var userid = checkid()
if (!userid) {
userid = window.MB_viewerId; //own page only if checkid() failed, so sequence is very important!
if (userid) {
console.log("data-owner success");
} else {
var pathArray = window.location.pathname.split('/');
///communities currently only digit, otherwise is always same with user profile, .e.g https://plus.google.com/+Dell/posts
if (pathArray.length > 2) {
if ((pathArray[1] == 'app') && pathArray[2] == 'basic') {
if (pathArray[1] != "communities") {
owner = pathArray[3]; //plus.google.com/app/basic/USERID/posts
} else {
owner = pathArray[4];
}
} else if (pathArray[1] == "communities") {
owner = pathArray[2];
} else if (/^[a-zA-Z0-9]$/.test(pathArray[1])) {
if (/^[0-9]$/.test(pathArray[2])) { //plus.google.com/u/1/USERID/posts
owner = pathArray[3];
} else { //plus.google.com/b/118094714132938124668 //currently no profile pic
owner = pathArray[2];
}
} else {
owner = pathArray[1];
}
if (!/^\d+$/.test(owner)) {
if (owner[0] != '+') {
console.log("[1] Failed. Unable to recognize userid.");
throw "stop execution";
} else {
m_url = "https://plus.google.com/app/basic/" + owner + "/"
console.log("Tryng..." + m_url);
var xhr = new XMLHttpRequest();
xhr.onreadystatechange = function () {
if (xhr.readyState == 4) {
var da = xhr.status;
if (da == 200) {
var r = xhr.responseText;
var rArray = r.match(/data-owner="([^ ]+)"/);
if (rArray.length > 0 && rArray[1]) {
userid = rArray[1];
console.log("[1] User id is:" + userid);
plusone_tab();
} else {
console.log("Failed parse data-owner");
throw "stop execution";
}
} else {
console.log("Failed request mobile URL");
throw "stop execution";
}
}
}
xhr.open("GET", m_url);
xhr.setRequestHeader("Content-type", "application/x-www-form-urlencoded");
xhr.send(null);
}
} else {
console.log("URL path got userid");
userid = owner;
}
} else {
console.log("[0] Failed. Unable to recognize userid.");
throw "stop execution";
}
}
}
if (userid) {
console.log("[0] User id is:" + userid);
plusone_tab();
}
步骤 5.
然后粘贴在
箭头 >> 的地方。按ENTER 键 (IE浏览器要按 CTRL+ENTER)。如下图所示。
跑了一会后,就会看见 Lady Gaga 的 +1 过的网址了。 她只 +1 过 5次。
如果没有 +1 过的话, 会显示 nothing :(
一次只显示20个网址, 如果要去下一页, 可以按最下面左下角的 "
More 更多" 按钮。
其它例子, 面子书创办人。
谷歌CEO/创办人。
Kevin Mitnick 喜欢的网站都是..
Linus Torvald 推荐过的唯一一个网址竟然是...
干杯 :)