你可以去 MAXMIND 注册(免费) 个账号然后下载最新 CSV 版本:

如果播放视频时加速,对 fps 有何影响?如何预测会 dropped 多少 frames?
mpv 确实可以 speed up 后如果仍可以满足 monitor 的 refresh rate Hz 就可以不 drop frames。
不过 165 Hz 要求 gpu+cpu 很高否则也是有问题(不然 multitasking 容易 drop frame)。
而且 144 Hz 或 120 Hz 都能被常见的 24 fps 完整除 (120 Hz 能被 youtube 常见的 30 fps 除)
,只有 165 Hz 怪怪的不能整除 (https://www.svp-team.com/forum/viewtopic.php?pid=63214#p63214)。
做个小实验验证一下:

[1] 30 fps x 2 倍速 = 60 fps,由于我 Monitor 59.99 Hz,不会 drop 任何 frame, ( ( (30 video fps * 30 秒) / (30 秒 / 2.0 speed) ) - 60 Hz) * (30 秒 / 2.0 speed) = ~0 frame。
[2] 120 fps 普通速,由于 120 超出 Monitor 能力 一倍,30 秒后会 dropped ( ( (120 video fps * 30 秒) / (30 秒 / 1.0 speed) ) - 60 Hz) * (30 秒 / 1.0 speed) = ~1800 frames (即总数的一半)
[3] 60 fps x 2 倍速 = 120 fps,由于 120 超出 Monitor 能力 一倍,30 秒后会 dropped (( (60 video fps * 30 秒) / (30 秒 / 2.0 speed) ) - 60 Hz) * (30 秒 / 2.0 speed) = ~900 frames (即总数的一半)
[4] 60 fps x 1.5 倍速,30 秒后会 dropped ( ( (60*30) / (30 /1.5) ) - 60 ) * (30 /1.5) = ~600 frames (即总数的三分之一)
预测 dropped 多少 frame 只能大概 ~,因为一: Hz 并非整数。二:时间和速度不担保 round 得精准,也因此我使用 --speed=1.99 而不是 2。 三:其它因素譬如 cpu/gpu/multitasking 可以随机 drop。 四:不清楚囧除非研究 mpv 源码 🌚
至于 YouTube player 我觉得 "Stats for Nerds" 的 frame dropped 信不过 🌚 (https://bugzilla.mozilla.org/show_bug.cgi?id=1578042)。我手机 app 60 Hz play 60 fps x 2 speed 却几乎没有任何 drop。
相关问题: https://video.stackexchange.com/questions/15857/what-happens-to-frames-when-you-speed-up-a-video-clip
MySejahtera 的隐私 bug,可以查看其它店的人流, 甚至更新资料。
有些非 Master branch 而看不到更新资料的页面,能通过 email 得知 `Hi contact_name`(有些填手机号)。
由于 bug 会被滥用,我就不公开方法了。(更新: 已被修复)



实验:







用 youtube-dl 和 you-get 下載 4 種視頻鏈接格式:
[1] 'https://www.facebook.com/<username>/videos/123/'
[2] 'https://www.facebook.com/<username>/posts/123'
[3] 'https://www.facebook.com/permalink.php?story_fbid=123&id=123'
[4] 'https://www.facebook.com/watch/?v=123'
[5] 手動下載。
實驗結果:
video detail page 的 'https://www.facebook.com/<username>/videos/123/' 或 /watch/ 或手動才能下載最高清視頻。
其餘兩個不僅僅有時下載不了,而是比較低清。
實驗總結:
選什麼鏈接下載並非 optional, 而是必須選 video detail page 的鏈接才能確保下載最高清視頻。

Android 上传 4 MiB (4032x3024) 的文件, PXL_20201022_141809183.NIGHT.jpg:
[1] 浏览器能下载 241 KiB (1440x1080) 的 JPEG 图。
[2] Android Facebook app 能下载 114 KiB (1080x810) 的 JPEG 图。
浏览器上传同样的 PXL_20201022_141809183.NIGHT.jpg:
[1] 浏览器能下载 509 KiB (2016x1504) 的 JPEG 图。
[2] Android Facebook app 能下载 109 KiB (1080x806) 的 JPEG 图。
实验总结:
要在 Facebook 下载别人最高清的图,上传和下载都必须用浏览器。下载才用浏览器则次之。下载用 Android Facebook app,甭管上传方式,都是最低清,没区别(Android 或浏览器上传都有比对方微小高的可能)。
其它因素:
[1] 此实验的 app 设置 SD/HD 上传没区别。
[2] 通过图库 app 的 "SHARE TO APPS" -> "News Feed" fb icon 上传,与直接在 fb app news feed 上传,两者没区别。
[3] 此实验 app 设置关闭 Data Saver。
[4] 设置朋友/公开权限不影响各下载方式的清晰度。
[5] Browser 的 Save image as, fullscreen "Save image as", "Download" 没区别。以前没 Download 按钮时, fullscreen 才比较高清所以才考虑这个因素。
[6] 以上的 Browser 只指 desktop www.facebook.com,而 m.facebook.com 的 "View Full Size" 则分别是 326 KiB(浏览器上传) 以及 206 KiB (Android 上传),皆介于 Browser 与 Android Facebook app 下载成绩的中间。
[7] 原图编码是 Baseline, 下载后的编码全是 Progressive, 所以不用担心不同编码影响结果。


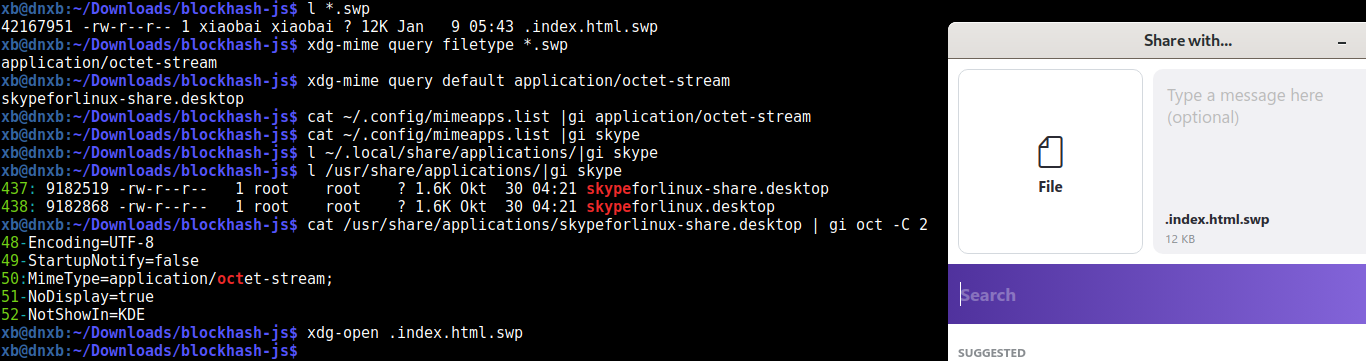
顺便吐槽下 Konsole 新设计, 它的 find dialog 以前 (Ubuntu 18) 是下方完整的 panel row。
现在 (Ubuntu 20) 则是悬浮小部分在右上方,掩盖我命令行的后端,只能全屏 + 特地上方留空才能截屏完整高亮的结果囧 🎃
不是神仙没预料要截屏而留空只能重运行, 但不是每个命令都能得到同样的 output + 浪费时间。
还有其它新设计很有问题,譬如 tab 打叉关闭很容易在换 tab 时误按 (右手用滑鼠与键盘交换的速度已很快,不喜太靠边的两个键 Ctrl+Tab)
, 明明以前 Ctrl+D 或偶尔滑鼠右键菜单关闭就完事不香么?
刚开始以为只是想多了, 可这几天我实实在在曾误关闭了几个需要留着的 output tab
,即使新设计检测有进程还在运行会有对话框都不能避免误关这种没进程但有重要 output 的 tab。
还有 scrollbar 太黑不懂如何调, 尝试各种 theme 设置都没效果。
看 changelog 都是讲为了更好,确定不是在逗? 🎃
我不介意改,但能不能提供设置让用户选择?
If it ain't broke, don't break it, Konsole!
If
user use bash -c "" will easy to get unexpected result if user just
copy-paste working code from existing shell session into bash -c "" (OR
extend existing bash -c "") and expect it same. But if user use single
quotes(outermost) consistently, then user can get rid a lot of trouble.
So, always use '' single quotes in outermost(of course you can insert "$var" inner to expand if really need while you aware of this pitfall).
Previously I thought bash -c "" OR '' is just favor of choice(sort of isolate process something) until one day I play around with find/xargs and I wonder why `bash -c "dd2=`echo 5` && echo $dd2"` print nothing and why some commands pattern only run correctly on second time(because second time that "global" "$variable" get initialized from first time).
Note that I'm not talking about export environment thing here. `bash -c ''` is just one of the fundamental every shell user MUST know or you waste your time when debugging commands, and worst, unnoticed hidden bug wait for trigger.

如果群组组员的主页 URL 是没用户名 (譬如 https://www.facebook.com/zuck 格式) 而只有 id (譬如 https://www.facebook.com/profile.php?id=12345 格式)
,那么群组的组员页面的 "View Main Profile" 按钮是 link 去 www.facebook.com 而不是该用户的主页。需要去网址栏删除 groups/<组id>/user/ 再浏览。
如果你只有 id 那么就可以减少 (当然, 不可能完全避免) 组里 stalker 们 stalk 你主页, 反之如果你是搞宣传的且希望在组里引流去你的 profile, 则劝你放个用户名。
我转换去新设计后早就注意到这个 bug 很久了(很明显好不),只是到现在都没去 fix 囧, fb 的员工懒到囧 😆。

我就奇怪做么 alarm ⏰ 常没声音,原来 slider 的 alarm volume bar 要超过一半才等于 clock alarm 的第一个 volume,wth 🥶🥶🥶🤖🎃🥃
Media volume 1/3 的声音就够了,所以 Alarm volume 也跟着调 1/3, 没想到是个大坑:

与上图 slider 相应的 volume, 在 clock app 的设置是 mute 囧:

来个全景经典画面, 左(slider 设置)1/3, 右 (clock app 设置) 是 mute, 两者名字都称 "Alarm volume" 囧, 应该坑了不少人, 不说了我迟到了 🌚:

你可以看到 (?<! b|dia)log(?![a-z]), 表示我要看到有 log 关键字的 line, 但是又不想包括 blog, dialog,logic, login 这些常见字眼。前面是 `?<!` , 后面是 `?<`, 区别只是前面多了一个 `<`。要添加的时候,先检查现成有没有才修改 (比如我要 exclude "dialog",我找到现成已有 "log", 那就在 "log" 那里 extend, 而不是加新的 `| |` )。
你可能会问有 "impossible" 为何没有常见的 "not possible", 因为 "not" 已拥有自己的 `| |`。所以不需要重复加 "not possible", "not able", "not found" 之类的 | |, 省很多。想一下,有 `not `的 log 是不是很多都是跟错误(或值得关注)有关系的?就是这么个玩法。block 也是同理,有 lock 了不需要 block。改的时候要小心, 譬如 dump 是包括 core.?dump 的哦。err 可能比较常改, 所以最好分 errno 和 interrupt 出来。
还有一些比较主观的讲究, 比如 disabling, revoking ... 我觉得没那么重要,重要的是 disabled, revoked, 所以我才放 disable 而不是 disabl。还有 pause 不是很重要,毕竟只是暂停,并非如 stop 或 cancel 那么重要。放太多会很 noise 所以要取舍。
最后第二个 `\?` 是黑人问号 ?, 如果问号 ? 在 log 是正常的就要拿掉或修改。此命令主要就是 universal template,不是直接用就完美,但起码有个起点让你稍微修改就搞掂。
最后则是常见的感叹号 "!", 排除常见的 `[ !` shell 格式和 `<! `html tag 以减少噪音, 不过仍然得保留常用来表达某些事物不等同而出错的 `!=` 符号。
有时你想了解上下文,可以加类似 -C 5 的 grep 选项或最后的 ' 前放多一个 `|` (不需要值) 即可显示全部不过仍然有搜索颜色看。
效果截图: